
Autonom8 Loans is a digital platform that simplifies retail loan processing
SEE HOW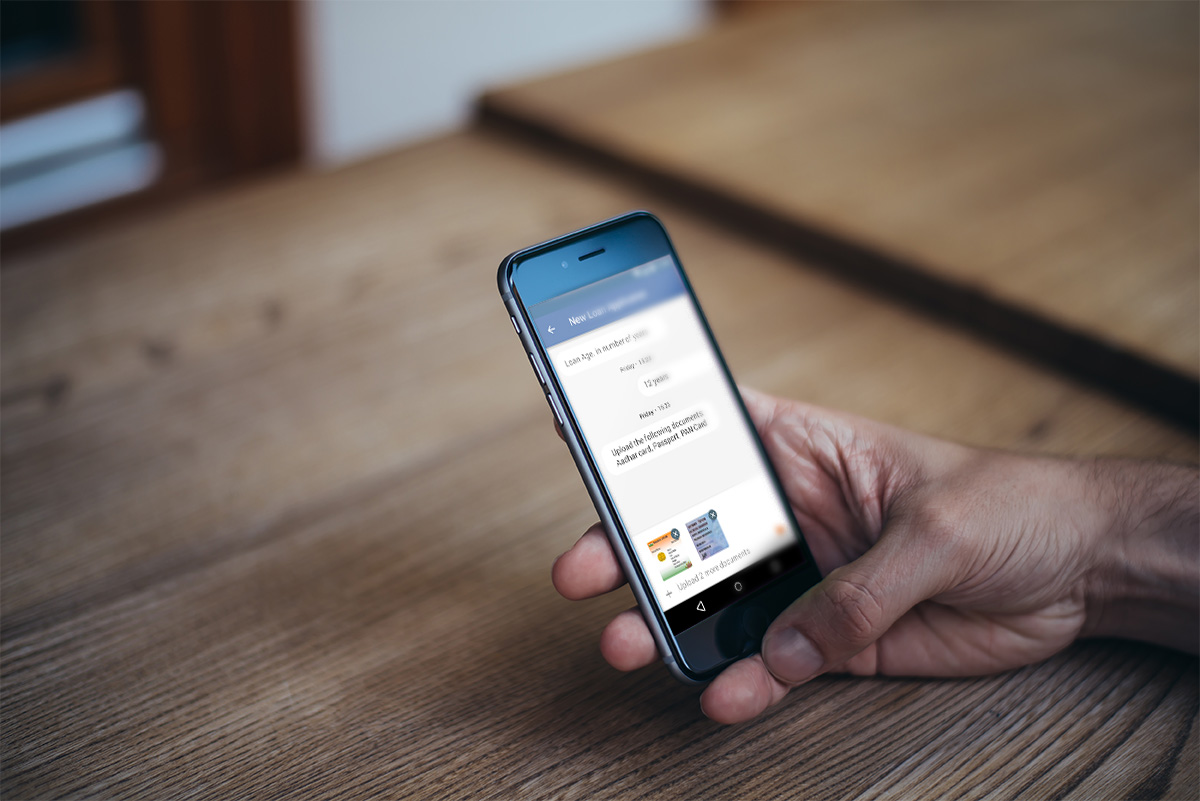
Digitize your loan process
in 3 simple steps
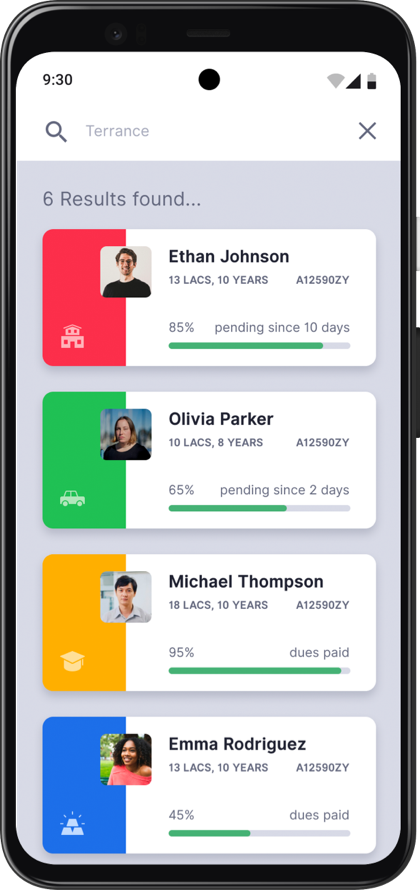
Image Parsing
Capture applicant data accurately

Real time validation
Process more loans per day
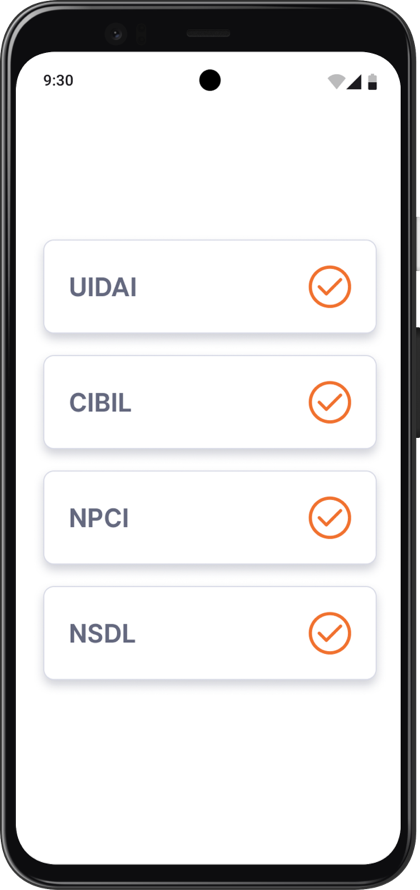
Smart Processing
Loan decisions in real time
Key features of the Autonom8 Loans platform
In the era of FinTech competition,
Autonom8 Loans gives you the digital edge to win your customers

Speed
Reduce loan approval cycle time from days to minutes

Agility
Launch new products faster to market

Compliance
Enforce policy & detect frauds early

Personalize
Create unique branding and customized flow variations

Machine Learning
Use AI to make smarter decisions

Governance
Full visibility and control across operations
My challenge isn't demand, but the frustrating pace of loan sanction. How I wish we had the digital capabilities to delight our customers.
Business Head (Retail Loans)
